“全球大模型第一股”智谱“未发先火”的新模型,终于露出庐山真面目。
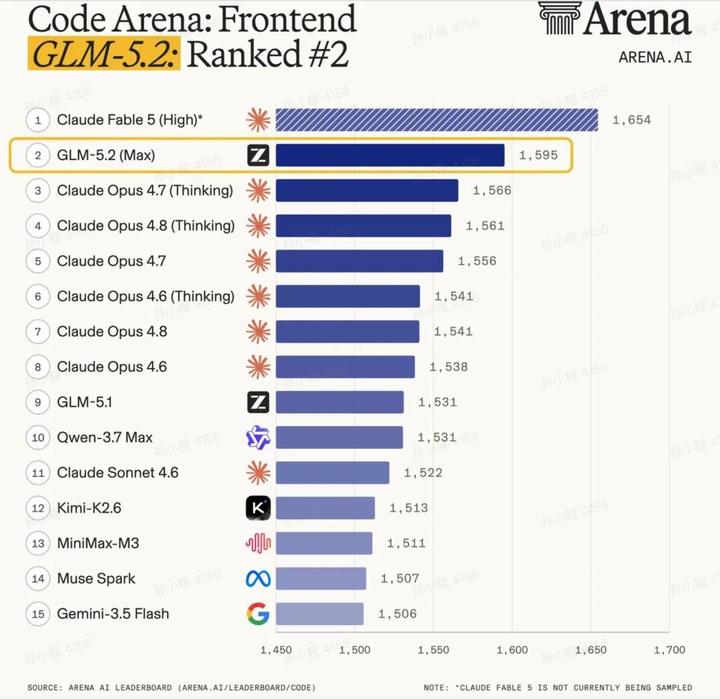
6月17日凌晨,智谱在海外上线并开源GLM-5.2。在全球百万用户参与盲测的前端开发评估系统Code Arena上,GLM-5.2取得全球可用模型第一的表现。
需要补充的是,GLM-5.2踩中的时机颇为精准,让其早已积累了极高的关注度。
6月12日,美国AI公司Anthropic受紧急出口管制指令影响,暂停其Claude Fable 5、Mythos 5两款最新模型的开放。在这一背景下,6月13日,智谱宣布GLM-5.2全量开放,称“前沿智能不应只属于少数人,也不应被少数规则随时收回。它应该开放、可用、可构建,并服务于每一位开发者”。
简而言之,当闭源海外大模型的服务可得性与合规性遭到冲击时,智谱释出了一个供给可控、可本地化部署且能力相当的选项,即GLM-5.2。
本次正式对外发布的GLM-5.2,其Coding(编程)能力得到进一步强化,最大亮点在于1M上下文和长程任务能力(Long Horizon Task),让模型在跨越数周、数月乃至数年的规划与执行中“不健忘”,更贴合程序员群体的使用需求。
智谱技术团队介绍,过去一年,行业衡量模型智能的标准正在迁移:从“答得多好”转向“能独立工作多久”,AI正在从对话者(talker)变成执行者(doer)。
但把时间线继续往前推,让AI独立“干活”需要克服一个难点:上下文。一个持续工作数小时的智能体,要经历数千次工具调用、读写数万行代码、积累大量中间状态。上下文窗口不够长,模型就被迫不断压缩、丢弃、再回忆,每一次压缩都是信息损耗,每一次遗忘都可能让任务在第N步偏离第2步定下的约束。
智谱技术团队分析称,长程任务的失败,很多时候不是模型不够聪明,而是它“忘了”。这就是1M上下文对长程任务的意义:它是延长模型有效工作时长的基础设施。
因此,GLM-5.2主攻长程任务能力,让AI不再只做即时问答,而能像人一样连续工作数小时、自主跑完一个完整的大型工程。智谱称,在 FrontierSWE、Terminal-Bench等多个权威评测中,GLM-5.2与当前海外最强的 Claude Opus 4.8仅相差约1%–4%,是排名最高的开源模型。
Demo显示,用一句话描述需求,它就能自主完成开发、联调、测试到打包上线,几小时内交付一个网页、手机、小程序都能用的完整应用,而这过去往往需要一支团队干上数周。
算力基础设施上,智谱介绍,GLM-5.2的线上推理依托多个国产算力平台,已在Day 0完成与华为昇腾、平头哥、摩尔线程、寒武纪、昆仑芯、沐曦、燧原、海光、壁仞等国产算力平台的推理适配,在国产芯片集群上实现高吞吐、低延迟、大并发的稳定运行。
透过智谱本次发布可以窥见,模型厂商产品性能的提升,正在更直接地传导为资本市场的估值表现,两者关联性明显增强。
摩根大通在研报中指出,随着行业变现路径逐渐向API、编码、智能体和企业工作流收敛,模型能力领先性变得更为关键,定价权将更多取决于能力,而非产品覆盖广度或使用规模。
东方证券认为,由于国内模型性能领先、多数模型开源、API调用成本较低,使得中国模型在OpenRouter等Token分发平台上占据领先位置,国产模型的API调用量有望进一步提升,基于国产模型的算力与Token服务需求将维持较好的增速和景气度。
作者:孙小程

作者:上海证券报








