近日,北京大学人工智能研究院孙仲研究员团队联合集成电路学院研究团队,成功研制出基于阻变存储器的高精度、可扩展模拟矩阵计算芯片,首次实现了在精度上可与数字计算媲美的模拟计算系统。
该芯片在求解大规模MIMO信号检测等关键科学问题时,计算吞吐量与能效较当前顶级数字处理器(GPU)提升百倍至千倍。相关论文于10月13日刊发于《自然·电子学》期刊。
对于大多数习惯了数字计算机(0和1)的公众而言,“模拟计算”是一个既古老又新奇的概念,什么是模拟计算呢?
孙仲首先用生动的比喻对其进行解释:“现在的所有芯片都是数字计算,数据都需要先转换成0和1的符号串。比如数字‘十’,需要转译成‘1’和‘0’,计为‘1010’。”如果用二进制来表示“1+1=2”,则应该记作“1+1=10”。
孙仲说,“而模拟计算则无需这层‘转译’,它是一种‘类比计算’,可以直接用连续的物理量(如电压、电流)来类比数学上的数字。比如,数学上的‘十’,可以直接用十伏或十毫伏的电压来表示。”
模拟计算机在计算机发展早期(上世纪30至60年代)曾被广泛应用,但随着计算任务日益复杂,其精度瓶颈凸显,逐渐被数字计算取代。孙仲指出,此次研究的核心正是要解决模拟计算“算不准”这一痛点。

课题组合影
当前的市面上的主流CPU和GPU都是数字芯片,并都采用冯诺依曼结构,将计算和存储功能分开,通过01数字流的编译+计算+解码实现信息计算和传输。
基于阻变存储器的模拟计算的优势之一在于取消了“将数据转化为二进制数字流”这一过程,同时不必进行“过程性数据存储”,进而将数据计算过程与数据存储合而为一,实现算力解放。
孙仲指出,与其他“存算一体”方案对比,国内外许多团队集中于研究矩阵乘法(AI推理的核心),而他的团队特色在于专注于更具挑战性的矩阵方程求解(AI二阶训练的核心)。矩阵求逆操作要求的计算精度极高,时间复杂度达到了立方级。而模拟计算凭借物理规律直接运算的方式,具有低功耗、低延迟、高能效、高并行的天然优势,只要能够不断降低计算误差,不断提升计算精度,将为传统GPU的算力解放带来爆炸性突破。
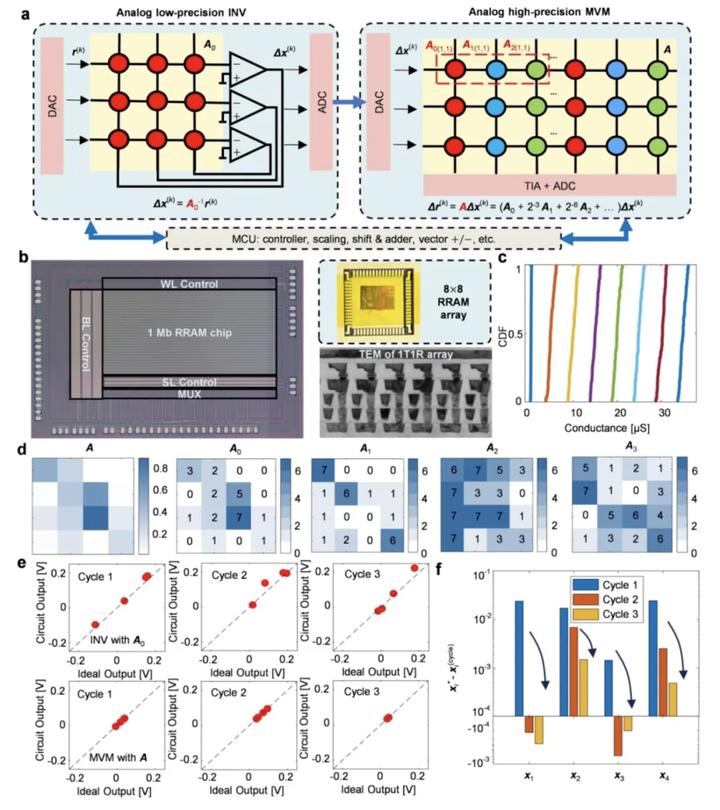
高精度全模拟矩阵计算求解矩阵方程
在计算精度方面,团队在实验上成功实现16×16矩阵的24比特定点数精度求逆,矩阵方程求解经过10次迭代后,相对误差可低至10⁻⁷量级。在计算性能方面,在求解32×32矩阵求逆问题时,其算力已超越高端GPU的单核性能;当问题规模扩大至128×128时,计算吞吐量更达到顶级数字处理器的1000倍以上,传统GPU干一天的活,这款芯片一分钟就能搞定。

孙仲
关于应用前景,孙仲认为,模拟计算在未来AI领域的定位是强大的补充,最有可能快速落地的场景是计算智能领域,如机器人和人工智能模型的训练。
谈及与现有计算架构的关系,孙仲强调未来将是互补共存:“CPU作为通用‘总指挥’因其成熟与经济性而难以被淘汰。GPU则专注于加速矩阵乘法计算。我们的模拟计算芯片,旨在更高效地处理AI等领域最耗能的矩阵逆运算,是对现有算力体系的有力补充。”
来源/北京大学、科技日报
监制/乔申颖
审核/于浩
编辑/刘畅(见习)
校对/刘莉
作者:经济日报








